Les règles d’or du web scraping – Partie I
Connaissez-vous le web scraping? Cette technique qui consiste, grâce à la programmation de robots, d’aller fouiller dans des bases de données publiées sur internet pour en extraire en quelques minutes, parfois quelques heures, des informations que l’homme mettrait plusieurs mois à compiler. Notre collaborateur spécial, Nael Shiab, nous explique en quoi cette prouesse technologique peut se révéler intéressante pour les journalistes.
Par Nael Shiab, collaboration spéciale
Vous rappelez-vous quand Twitter a perdu 8 millards de dollars en quelques heures à peine? C’était à cause d’un web scraper (souvent affectueusement surnommé “robot”), un outil utilisé depuis longtemps par certaines entreprises, mais aussi par les plus geeks des journalistes!
Petit retour en arrière. En avril dernier, Twitter devait annoncer ses résultats trimestriels une fois les marchés boursiers fermés. Les résultats étant un peu décevants, Twitter voulait éviter une vente brutale de ses actions. Malheureusement, à cause d’une erreur, les résultats se retrouvent en ligne pendant 45 secondes, alors que les courtiers sont encore au travail.
Ces quarante-cinq secondes permettent alors à un robot programmé pour faire du web scraping de détecter la publication, la formater et la publier automatiquement sur… Twitter! Ô ironie!
Et oui, de nos jours, les robots aussi ont des scoops de temps en temps!
Un web scraper est tout simplement un programme informatique qui lit le code html des pages web et l’analyse.
Avec ce genre de “robot”, il est possible d’extraire des données et des informations qui sont présentées sur des sites web.
#BREAKING: Twitter $TWTR Q1 Revenue misses estimates, $436M vs. $456.52M expected
— Selerity (@Selerity) 28 Avril 2015
Une fois le tweet publié, les marchés boursiers s’emballent. C’est l’hécatombe pour Twitter. Selerity, la compagnie spécialisée dans l’analyse en temps réel, devient la cible de nombreuses critiques. La compagnie s’explique quelques minutes tard.
Today’s $TWTR earnings release was sourced from Twitter’s Investor Relations website https://t.co/QD6138euja. No leak. No hack. — Selerity (@Selerity) 28 Avril 2015
En fait, 45 secondes, c’est une éternité pour un robot. Selon la compagnie, trois secondes ont suffit à son programme pour publier les résultats!
Web scraping et journalisme
De plus en plus d’institutions publient leurs données sur Internet. Par conséquent, le web scraping (ou extraction de données) devient un outil de choix pour les journalistes sachant coder.
J’ai notamment utilisé la technique du web scraping pour comparer les prix de plus de 12 000 produits de la SAQ avec environ 10 000 produits de la LCBO, pour le Journal Métro.
Mes confrères de Radio-Canada Florent Daudens et Pasquale Harrison-Julien ont aussi utilisé cette technique pour comparer les prix des loyers proposés sur Kijiji.
Autre exemple: lorsque j’étais à Sudbury, je m’intéressais aux inspections sanitaires dans les restaurants. Tous les rapports sont publiés sur le site web du Service de santé publique. Mais impossible de télécharger l’ensemble des résultats. Vous ne pouvez les consulter que pour un restaurant à la fois.
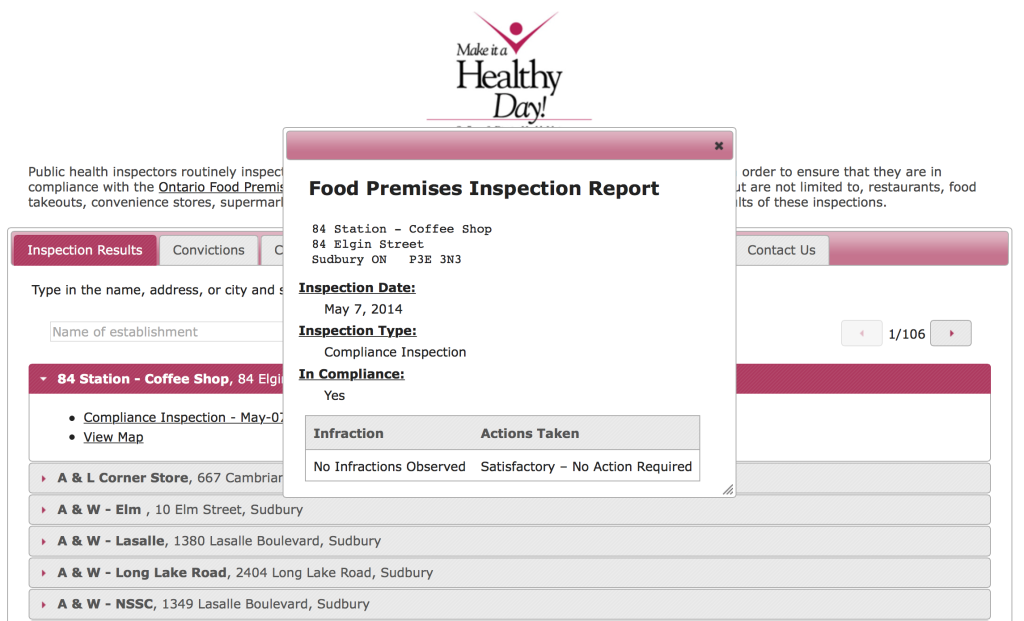
J’ai demandé l’ensemble de la base de données où se trouvent tous les résultats. Après avoir essuyé un refus, j’ai fait une demande d’accès à l’information. En bout de ligne, le Service de santé publique réclamait plus de 2000$ de frais pour pouvoir traiter ma demande…
Alors, plutôt que de payer, j’ai décidé de coder mon propre robot, qui irait extraire l’ensemble de leurs résultats, directement sur leur site web. Voici le résultat:
Codé en langage Python, mon robot prend contrôle de Google Chrome, grâce à la librairie Selenium (merci Jean-Hugues Roy de m’en avoir parlé!). Il clique sur chacun des rapports des 1600 institutions inspectées par le Service de santé publique et en extrait les informations. Le tout est ensuite envoyé dans un fichier Excel.
Faire tout ça à la main aurait pris des semaines… Avec mon robot, ça se fait en une nuit!
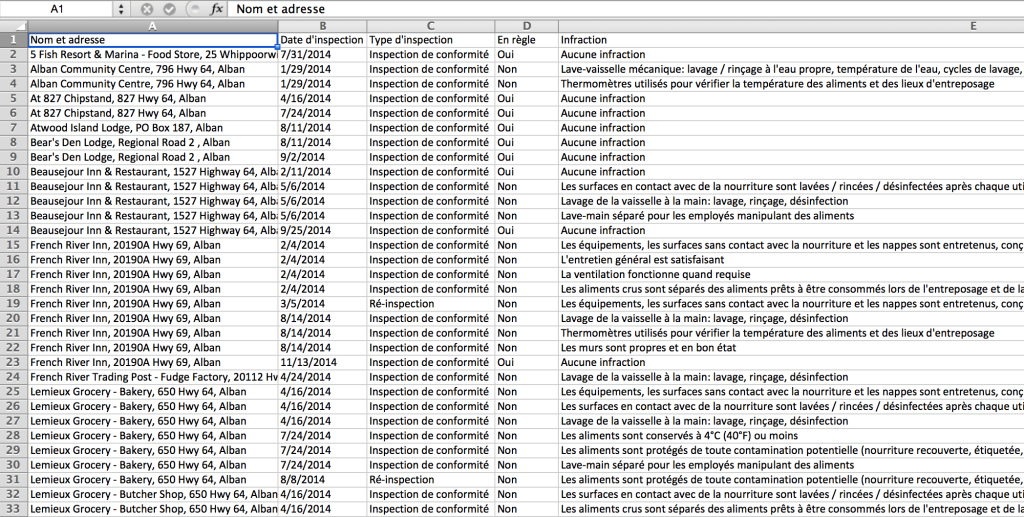
Mais alors que mon robot recueillait infatigablement des milliers de lignes de données, une question ne cessait de me tourmenter: quelles sont les règles éthiques du web scraping?
Avons-nous le droit de récupérer n’importe quelle information glanée sur le Web? Où se situe la limite entre le hacking et le scraping? Et comment s’assurer de la transparence du processus, tant pour les institutions visées que pour le public qui lira le reportage?
Comme journalistes, étant donné la nature de notre travail, nous nous devons d’être une éthique irréprochable. Sinon, comment le public pourrait-il croire les faits que nous rapportons?
Malheureusement, le Guide de déontologie de la Fédération professionnelle des journalistes du Québec, adopté en 1996 et amendé en 2010, commence à se faire vieux et n’apporte aucune réponse précise à toutes ces questions.
Les principes éthiques de l’Association canadienne des journalistes, bien que plus récents (2011), ne sont pas non plus d’une grande aide.
Comme me le disait Jean-Hugues Roy, professeur de journalisme à l’UQAM : « Ce sont de nouveaux territoires. Il y a plein de nouvelles techniques qui arrivent qui nous forcent à repenser l’éthique, et l’éthique doit évoluer avec les outils. »
Alors, à défaut d’avoir trouvé les réponses à mes questions, j’ai décidé d’aller les chercher moi-même, en contactant les différents journalistes de données au pays! Compte-rendu dans la deuxième partie de ce dossier.
PS: Pour ceux que ça intéresse, j’avais publié un petit tutoriel de web scraping en février dernier. J’y expliquais comment extraire les données du site web du Parlement du Canada!

Nael Shiab est journaliste de données au quotidien Métro à Montréal. Vous pouvez le suivre via ses comptes Twitter, Facebook ou LinkedIn.
À voir aussi:
Démystifier le journalisme de données
Les experts sont-ils vraiment experts?
Affaire Bugingo: Plus jamais ça?
Isabelle Hachey: «Je n’imaginais pas qu’on en parlerait autant»
Affaire Bugingo: le journalisme québécois sous le choc